The word “guardrails” has quietly come to mean everything. Browse any vendor page in 2026 and you’ll see it stretched across content filters, identity scoping, runtime monitoring, prompt hardening, and access control — all bundled under one reassuring label. That looseness is a problem. If a term covers everything, it specifies nothing, and users can’t tell whether two products that both “add guardrails” are doing remotely the same thing.
This post is an attempt to be precise. We’ll define each layer of the modern agent-security stack, say exactly what it sees and what it can do, and be honest about where each one stops. Then we’ll place Kyvvu on that map.
First, a working definition of an agent
An agent is a system that pursues a task by taking a sequence of steps. A step is a discrete action: calling a tool, reading a resource, sending a message, invoking a model, fetching a credential. The task has state, and steps are path-dependent — what’s safe at step 12 depends on what happened at steps 1 through 11.
This matters because most security controls were designed for a world of single, stateless requests. An agent run is neither single nor stateless, and that mismatch is the source of most of the gaps below.
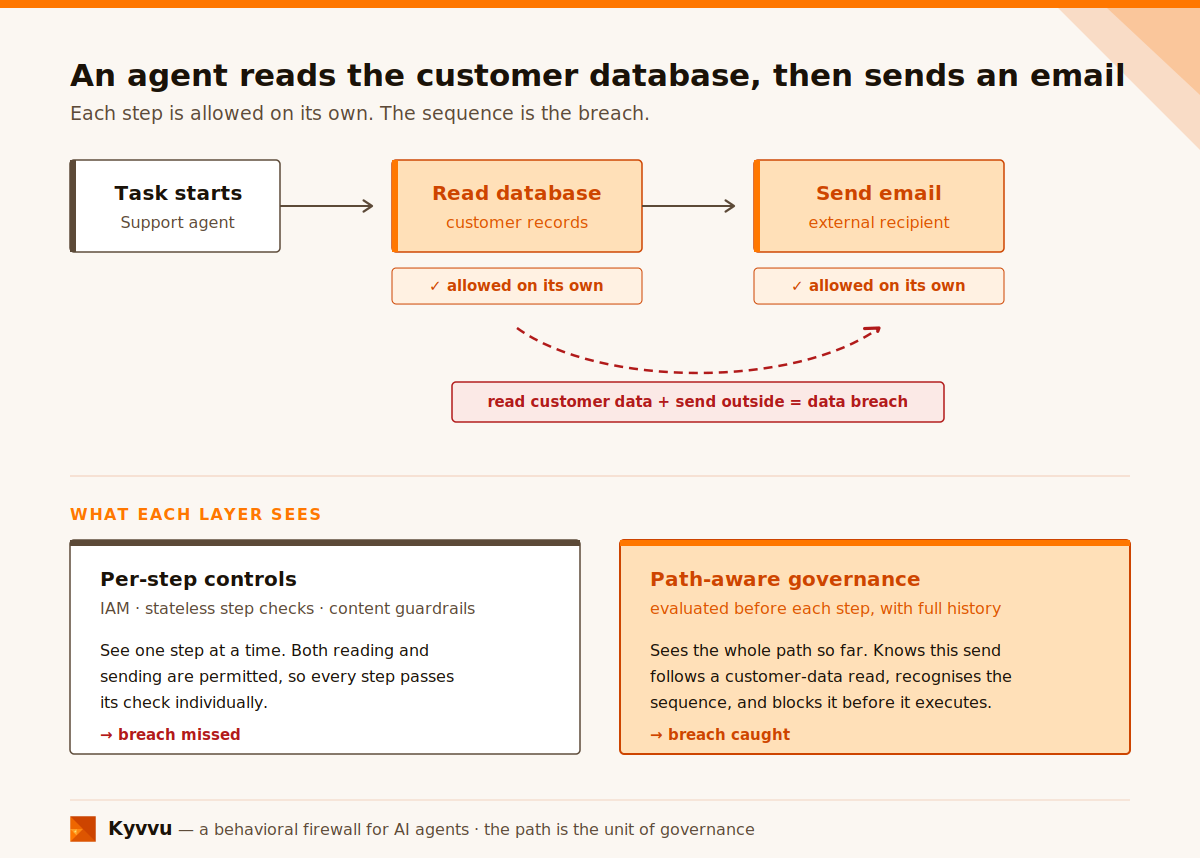
One example will run through this whole post, because it’s the simplest thing that breaks almost every layer: an agent reads from a customer database, then sends an email. Reading the database is fine — it’s allowed to. Sending email is fine — it’s allowed to. Reading customer data and then emailing it outside the org is a potential data breach. The violation isn’t in either step. It’s in the sequence.
It’s worth saying this isn’t a threat we simply conjured to sell a product. Anthropic’s Zero Trust for AI Agents framework, published yesterday, names this exact pattern — legitimate tools chained into a harmful sequence — as a live threat, noting that because every action runs through trusted channels under valid credentials, conventional monitoring sees nothing wrong. We agree completely on the threat. Where we differ is the remedy: that framework answers the sequence problem with per-action authorization and behavioral detection — drift baselines, anomaly flags — rather than enforcement over the path itself. The closest it comes to reasoning over the trajectory sits in its most advanced tier, and even there it’s detection, not a hard block. Keep that distinction in mind; it’s the one this whole post turns on.
Why runtime is the whole game
There’s a deeper reason agents break the usual playbook. With conventional software, you can largely guarantee behavior at development time. The program does what the code says it does. You bound it with types, tests, static analysis, code review, and — at the limit — formal verification. By the time you ship, the space of possible behaviors is fixed and inspectable. Runtime is where the verified program merely executes.
Agents invert this. An agent’s behavior isn’t written in the code; it’s generated at runtime by a probabilistic model reacting to inputs you didn’t see at build time — user requests, retrieved documents, tool outputs, other agents. The same agent, same code, same tools, can take entirely different paths on two runs. You cannot read the source and know what it will do, because the source doesn’t contain the behavior. The behavior happens live.
This is why red-teaming — genuinely valuable, and a category seeing real investment in 2026 (Patronus, General Analysis, the adversarial-testing side of Lasso and others) — is necessary but not sufficient. Red-teaming probes an agent before deployment with adversarial inputs to find failure modes. But it is sampling the behavior distribution, not bounding it. Passing ten thousand red-team scenarios tells you the agent didn’t misbehave on those ten thousand; it says nothing guaranteed about the ten-thousand-and-first path a real user, or a poisoned document, will induce in production. Design-time testing for agents is like crash-testing a driver, not certifying a circuit.
So the question isn’t can we verify the agent before we ship it — for the interesting properties, we can’t, the way we can with deterministic code. The question is what’s watching when it runs. That’s the lens for everything below: each layer is, in the end, judged on what it can enforce at runtime, on the path the agent actually takes.
The layers, defined precisely
1. Prompting (and model-level safety)
What it is: Instructions baked into the system prompt (“never reveal secrets,” “refuse harmful requests”), plus the safety training inside the model itself.
What it sees: The conversation. Nothing outside it.
What it can do: Influence the model’s intentions. It cannot enforce anything — it’s a request, not a constraint.
Where it stops: Prompts are advisory. They’re subject to prompt injection, they degrade over long contexts, and they offer no audit trail, no policy customization independent of the model, and no ability to actually block an action. Model-level safety reduces harmful outputs but doesn’t eliminate them, and it’s identical for every customer regardless of your specific policies. Useful as a first nudge; never a control.
2. Identity & access management (IAM)
What it is: Giving the agent its own identity, scoping what credentials and resources that identity can reach. Increasingly framed as “Zero Trust for agents.”
What it sees: The identity making a request and the resource being requested.
What it can do: Decide whether this identity may access this resource, at the level of tokens, roles, and permissions. This is mature, essential, and the correct foundation.
Where it stops: IAM is stateless and identity-centric, not behavior-centric. It answers “is this agent allowed to touch the customer database?” and “is this agent allowed to send email?” — and if the agent legitimately needs both, the answer to each is yes. It cannot answer “this agent just read the customer database and is now sending email outside the org — is that pattern allowed?” Both individual actions are permitted; the sequence is the breach. IAM doesn’t see sequences.
3. “Is this step allowed?” — stateless step checks
What it is: A check, before each step executes, that asks whether the step is permitted. In its simplest form this is just access control relocated to the agent loop.
What it sees: The current step in isolation.
What it can do: Allow or deny based on the step’s properties — the tool being called, the target, the verb (GET/POST/PATCH/DELETE), the data involved.
Where it stops: “Stateless” is the whole limitation. Evaluating each step on its own merits misses everything path-dependent — including our running example, since “send email” passes a per-step check no matter what the agent read a moment earlier. It’s strictly better than nothing and strictly weaker than reasoning over the trajectory. The interesting threats live in the relationship between steps, not in any single one.
This is the layer where most of the new “agent governance” tooling actually sits. Microsoft’s open-source Agent Governance Toolkit (April 2026), for instance, frames itself around three questions — is this action allowed, which agent did it, and can you prove it — with deterministic, sub-millisecond, per-action policy checks. That’s a genuinely useful combination of stateless step checking, identity, and audit, and it’s a good signal that the category is maturing. But the design point is per-action: it evaluates the step in front of it, not the path behind it. (Microsoft’s other agent release, Entra Agent ID, which reached GA in April 2026, is squarely the IAM layer above — agent identities, Conditional Access, lifecycle governance.)
4. Guardrails (the term, used correctly)
Here’s our narrow definition, and we’ll defend it: guardrails are input/output checks on the steps of a task. They inspect what goes into a step (the prompt, the tool arguments) and what comes out (the model response, the tool result), and they flag, redact, or block based on content.
What they see: The content of a single input or output — text, arguments, payloads.
What they can do: Detect prompt injection, scan for PII, classify content for safety categories, redact sensitive fields, enforce format constraints. Modern implementations run this in well under a second.
Where they stop: Guardrails are content classifiers operating on one input or output at a time. They’re excellent at “does this text contain a credit card number?” and blind to “is this the kind of action this agent should be taking right now, given everything it’s already done?” Content safety is not the same as behavioral safety. A perfectly clean-looking tool call can still be the wrong call. Guardrails check the contents of the step; they don’t reason about the step’s place in the task.
This is why we resist the umbrella usage. Calling identity management, access control, and trajectory reasoning all “guardrails” erases the distinction between checking content and governing behavior — and that distinction is exactly where agent risk concentrates.
A note on human approval and PII inspection
Two things often get filed under “guardrails” that deserve their own treatment: human-in-the-loop approval and PII inspection (whether by regex, by an LLM classifier, or by a person). These are real and valuable. But it’s worth being precise about what they are relative to governance.
They are actions the path might be required to take — not the substrate that governs the path. “Pause and get a human to approve before sending this email” is itself a step: a gate inserted into the trajectory. “Run this output through a PII check” is a step too, one that returns a result with some degree of certainty (a regex is crisp; an LLM classifier returns a probability). The right way to think about them is as steps a policy can mandate, insert, or condition on — not as the thing doing the governing.
This is exactly how Kyvvu treats them. A policy can require a human-approval gate before a sensitive step, or require that an output pass a PII check, and can branch on the outcome (and its confidence) of that check. Approval and inspection become first-class, governed actions on the path — composable with everything else — rather than a separate, parallel safety mechanism bolted on the side. The path is the unit of governance; approvals and checks are moves within it.
5. LLM routers / AI gateways
What it is: A proxy that sits between the agent and the model providers. It routes requests to the right model, tracks cost and usage, and increasingly applies guardrails and policy at the chokepoint. It’s worth being precise here, because the category is often described more broadly than it is.
What it sees: The model traffic that flows through it — the prompt (which includes your system instructions, the conversation, and the tool definitions) on the way out, and the model’s response on the way back. Crucially, when an agent calls a tool, the part the gateway sees is the model’s decision to call it: the tool name and the arguments the model produced. The actual tool execution — your agent’s runtime taking that decision, querying your database, and receiving rows back — happens agent-side and does not pass through a pure LLM router. (It typically sees those results only on the next hop, if and when they’re fed back into another model call.)
A gateway can be built to proxy the tool calls themselves too — sitting in front of your tools and APIs as an egress proxy. But that’s a broader thing than an LLM router, and the distinction matters: the more of your data path you route through an external proxy, the more of your data leaves your environment. Lumping both under “gateway” hides exactly the trade-off a user needs to see.
What it can do: Centralize model control, swap providers, enforce content guardrails on prompts and responses, log everything. Genuinely convenient as a single point of control for model traffic.
Where it stops — and this is the one to sit with: A gateway is in the data path for whatever it proxies. To enforce content policy on your model traffic, that traffic — prompts, the tool arguments your model emits, retrieved documents you’ve stuffed into context — has to travel to the gateway. If it also proxies your tools, the data in flight to those tools goes with it. If that gateway is a hosted SaaS, your sensitive data is now leaving your environment to be inspected by a third party. For regulated workloads (health, finance, anything under GDPR or the AI Act), that’s often a non-starter or a serious compliance burden. The architecture that makes a gateway convenient — route it all through one external point — is precisely what makes it a data-residency problem. And note what even a full gateway still can’t easily do: reason about the trajectory. It sees a stream of requests, but enforcing “given the last 50 steps, this one isn’t allowed” is not what a routing proxy is built for.
This is also where most of the commercial agent-security vendors have landed. A real category has formed in 2026 — Lasso, NeuralTrust, Noma, Prompt Security, Cisco AI Defense and others, enough that Gartner now publishes a market guide for the space. They’re strong at discovery (finding every agent and MCP server in your estate), at the design-time red-teaming discussed above, and at posture assessment. But on the runtime enforcement side, the dominant pattern is exactly the one above: inline protection “at the proxy, API, or AI Gateway layer,” as one vendor puts it. That’s the same architectural trade — your traffic flows through their inspection point — and the same two limits: it’s content-and-intent classification at a chokepoint, and it asks your data to come to the enforcement.
6. Credential brokering and the MCP boundary
A newer approach governs agents at the moment they authenticate to a tool. Instead of long-lived keys baked into the agent, a broker issues short-lived, task-scoped credentials, and policy is checked when a credential is requested — typically at the MCP layer or via an agent runtime CLI. No credential, no call. Keycard is the clearest recent example, and they get one thing genuinely right that the gateway category doesn’t: they issue credentials but explicitly do not proxy the data — the resulting token goes straight from the agent to the API, so this is not a data-residency story. Against static secrets and shared service-account keys, this is a real step forward, and it gives security teams a clean record of who asked for access to what.
What it sees: the tool-access request at the boundary — which agent, acting for which user, on which device, requesting which resource, in service of which task.
What it enforces: whether to issue (or deny) a credential, scoped and time-bounded.
Where it stops. Three places.
Coverage. The broker only governs tools it sits in front of. Servers and agents you control can be instrumented with the SDK; external or third-party MCP servers either need to be routed through the broker’s own proxy (which gives back some of the architectural advantage above) or go ungoverned. Shadow MCP — the agent that pip-installs a community server at runtime — is the hard case.
Granularity. Once a task-scoped token is issued, the broker typically steps out of the loop and the downstream service verifies the token on its own. It governs the request for access, not the use of access. A token scoped to db:customers:read can read one record or the whole table; both look identical at the credential boundary. Per-token scoping is not per-call enforcement.
Path. A credential to read customer data and a credential to send external email are each individually reasonable. The breach lives in their sequence, and no single credential check can see a sequence — the broker is evaluating the request in front of it against an identity and a task tag, not against everything the agent has already done on this path.
This is the gap access control has always had, in a more modern form. It’s also exactly why we built Kyvvu where we did.
A summary of the map
| Layer | Sees | Enforces | Stateful? | Data leaves env? |
|---|---|---|---|---|
| Prompting / model safety | The conversation | Nothing (advisory) | No | No |
| Identity & access (IAM) | Identity + resource | Access by identity | No | No |
| Stateless step checks | One step | Allow/deny per step | No | No |
| Guardrails (I/O checks) | One input or output | Content flag/redact/block | No | Depends on impl. |
| LLM router / gateway | Model traffic (prompts, responses, tool-call args) | Routing + content policy | Limited | Often yes (if SaaS) |
| Credential brokering | Credential requests at the boundary | Whether to issue a credential | Per-task, not per-call | Credentials only, not data |
The pattern across the table: the controls that are stateless miss path-dependent threats, and the control that centralizes (the gateway) does so by putting itself in your data path. Nobody on this list reasons about the full trajectory of a task while keeping your data inside your walls.
The tempting non-answer: just make agents smaller
There’s one more approach worth naming, because it’s genuinely appealing and genuinely insufficient: isolation. Make each agent as small as possible. Give it the fewest tools you can. Split the database-reader from the email-sender so no single agent can do both. Our running example “solves” itself — the agent that reads customer data simply has no email tool.
For narrow, well-understood workflows this is good engineering, and you should do it where you can. But as a governance strategy it doesn’t hold:
- It doesn’t scale. Every new capability means re-reasoning about which combinations are now reachable. The number of dangerous sequences grows combinatorially with tools; the number of agents you’d need to keep them apart grows with it.
- It forfeits the upside. The whole point of agents is composing capabilities to handle open-ended work. An agent that can read the database and can send email is enormously useful — that’s a customer-support agent, a reporting agent, an outreach agent. Lobotomizing it to be safe throws away the reason you built it.
- It just relocates the problem. Multi-agent systems re-create the exact sequence across agents: agent A reads, hands off to agent B, agent B emails. Now the dangerous path spans two agents and no per-agent isolation sees it.
Isolation is a useful constraint, not a governance model. The goal isn’t to make agents too weak to be dangerous — it’s to let them be powerful and still keep them on the rails.
Where Kyvvu sits
Kyvvu is a behavioral firewall for AI agents: runtime policy enforcement over the path of a task. It’s the layer that’s missing from the map above — and it’s designed to get the two hard things right at once.
It reasons over the trajectory, not the isolated step. Every action an agent takes is modeled as a (step_type, scope, verb) triple, evaluated against policy before it executes, with the full history of the task available to the decision. This is what lets Kyvvu answer the questions the stateless layers can’t: not just “is this step allowed?” but “is this step allowed given everything that came before it?” Our running example — read the customer database, then send an external email — is a single policy Kyvvu can express and block, while letting the same agent keep both tools for the legitimate cases. IAM, stateless checks, and content guardrails each see only an innocent fragment of it.
It runs in-process, on your premises. Kyvvu evaluates policy locally, inside your own environment, in the agent’s own process — with sub-millisecond evaluation latency (published benchmarks: 296µs p99 with 100 policies and 50 steps of history). It is not a gateway. Your prompts, tool arguments, retrieved documents, and customer data never travel to us. There is no external chokepoint in your data path.
Only the policy leaves — and even that is yours. The only thing that crosses the boundary is the policy itself, submitted encrypted. Your policy manifests live as YAML bundles in your own git repository, linked to Kyvvu through the UI — git is the source of truth, versioned and auditable like any other infrastructure-as-code. You author and own your policies; Kyvvu enforces them where your agents actually run.
This is the distinction that matters most against the gateway category. A hosted gateway asks you to route your sensitive data out to inspect it. Kyvvu inverts that: the enforcement comes to your data, not your data to the enforcement.
How Kyvvu complements the rest
To be clear, this isn’t an argument that the other layers are wrong — they’re complementary, and a serious deployment uses several:
- Keep your IAM. It’s the right foundation for identity and coarse access. Kyvvu reasons about behavior on top of it.
- Keep your content guardrails. PII scanning and injection detection on individual inputs and outputs are valuable. Kyvvu governs the behavior those checks can’t see.
- Use a gateway if you want one — for routing and cost. Just don’t mistake a data-path proxy for a behavioral control, and weigh what your data crosses to get there.
- Use credential brokering if you have the credential problem — short-lived, task-scoped tokens solve the static-secret risk genuinely well. Kyvvu sits a layer up, governing what the agent actually does with the access it was issued.
- Keep human approval and PII checks — and let Kyvvu orchestrate them. They’re valuable steps; Kyvvu decides when the path requires them and acts on their result.
Kyvvu is the trajectory-aware, on-premise enforcement layer that ties the picture together: built-in policy templates (OWASP agentic defaults, AI Act and GDPR built-ins), compound policies, and a runtime that’s fast enough to sit in front of every step without anyone noticing the cost.
The takeaway
If you remember one thing: with agents, behavior is a runtime property, not a build-time one — so content safety is not behavioral safety, and centralized control should not require centralizing your data. You can’t verify an agent’s behavior before it runs the way you can with deterministic code; what matters is what governs the path it actually takes, live. Most of today’s stack handles the easy half of each pair. Kyvvu was built for the other half — reasoning over the whole path of a task, at runtime, while keeping every byte of sensitive data exactly where it already lives.
Our approach to runtime governance is written up in full in our arXiv paper, Runtime Governance for AI Agents: Policies on Paths. And if you want to try it: pip install kyvvu, point it at a policy manifest in your own repo, and you have your first enforced policy in a few minutes.
A term that means everything points at nothing. The map is the point — pick your layers deliberately, and know which one is watching the path.
*Want to get started using Kyvvu? See docs.kyvvu.com.